Hype of techniek met potentieel?
Kan artificiële intelligentie struikelblokken in logistiek slopen?

Geen dag gaat voorbij zonder dat we met begrippen als artificiële intelligentie en deep learning om de oren worden geslagen. Toch weten velen onder ons nog niet wat dat precies inhoudt, laat staan wat AI binnen supply chain management kan betekenen. Tijdens Supply Chain Innovations in Antwerpen kregen we tekst en uitleg van professor Robert Boute, professor supply chain management aan de KU Leuven en Vlerick Business School, en Joren Gijsbrechts, PhD student aan de KU Leuven. Zij lichtten voor ons de verschillende soorten AI en hun potentieel binnen logistieke omgevingen toe. Daarbij bleek met name deep reinforcement learning wel eens de sleutel te kunnen worden als het op het oplossen van complexe logistieke problemen aankomt.
Dat de logistieke uitdagingen steeds groter worden, zal niemand ontkennen. Veel heeft te maken met de opkomst van e-commerce en omnichannelstrategieën, die dwingen om na te denken over een torenhoge service tegen zo laag mogelijk kosten. Bovendien waaien die hoge verwachtingen ook naar de b2b-business over, denken we maar aan de spare parts business. Tegenwoordig is óf kostenefficiënt óf snel zijn niet meer voldoende, het moet allebei. Voeg je bijvoorbeeld decentrale magazijnen aan een centraal magazijn toe om sneller te kunnen leveren, dan zal je die dus uiterst kostenefficiënt moeten beheren. Voor AI kunnen zulke zaken een mooie uitdaging vormen.
Wat transport in het bijzonder betreft, moeten we bovendien de CO2-uitstoot binnen de perken zien te houden.
Prof. Robert Boute: “De laatste jaren is de CO2-uitstoot met één procent gedaald. Maar willen we de doelstellingen van het klimaatakkoord van Parijs halen, dan moeten we die met acht procent verminderen. We moeten dus nog een tandje bijsteken. Dat geldt in het bijzonder voor de logistieke sector, die vandaag verantwoordelijk is voor acht à tien procent van de uitstoot. Dat is ook de enige sector waar de CO2-uitstoot nog steeds in stijgende lijn zit. Als wij daar zelf niets aan doen, dan zal de overheid ons daar ons wel toe dwingen, via taksen bijvoorbeeld. En dat zal nog meer aan de marges knagen.”
Eén mogelijkheid om specifiek op die laatste eis in te spelen, is synchromodaal transport. Daarbij wordt vrachtwagentransport binnen een hybride structuur gecombineerd met het spoor of binnenvaart. “Mooi in theorie, maar in de praktijk komt synchromodaal transport maar moeilijk van de grond”, meent prof. Robert Boute. “Een belangrijke reden daarvoor is dat er geen eenvoudige vuistregels zijn om te beslissen wanneer we best welke modus gebruiken. Daarom zijn Joren Gijsbrechts en ikzelf ons ook hier de vraag gaan stellen of artificiële intelligentie potentieel zou kunnen bieden.”

De gelaagdheid van artificiële intelligentie
Maar ‘first things first’. Wat is artificiële intelligentie precies en wat is nu het verschil met ‘machine learning’ en ‘deep learning’?
Joren Gijsbrechts: “Dat die begrippen nog niet in de hoofden van bedrijfsleiders zitten ingebakken, is geen schande. Meestal hebben ze die materie ook niet op de schoolbanken meegekregen. Nu artificiële intelligente op verschillende vlakken doorbreekt, beweren velen het begrip wel te kennen. Maar als je even doorvraagt, weten ze heel vaak niet wat AI voor hen kan betekenen.”
Artificial intelligence (zie figuur 1) is in feite het overkoepelende concept. Van zodra een machine intelligent genoeg is om iets te doen wat normaal gezien alleen een mens kan, bezit ze artificiële intelligentie. Als je dus gewoon een handeling programmeert, is dat ook AI. Dat noemen we ‘hard coded AI’, waarbij we machines exact gaan vertellen wat ze moeten doen.
J. Gijsbrechts: “Dat type AI bestaat al sinds de jaren ’50 en is dus allesbehalve nieuw. Onder AI valt machine learning, dat nieuwer is. Daarbij vertellen we machines niet meer expliciet wat ze moeten doen, maar leren we hen zaken te doen door hen te ‘belonen’ voor goed gedrag, uitgedrukt in een numerieke waarde.”
Het begrip ‘deep learning’, dat steeds vaker over de tongen rolt, is dan weer een bepaalde techniek binnen machine learning. Typisch voor die techniek is dat ze gebruikmaakt van artificiële neurale netwerken. “De Face ID op je gsm, bijvoorbeeld, is een mooi voorbeeld van hoe deep learning werkt”, aldus Jorgen Gijsbrechts. “Ook de homepod – de slimme speaker die in de VS al helemaal is ingeburgerd – is een typisch voorbeeld. Naast de HomePod van Google is er bijvoorbeeld ook de Amazon Echo en de Google Home.”
De deep learning applicaties die vandaag opduiken, zijn typische voorbeelden van narrow AI. Dat wil zeggen dat ze zeer goed zijn in één specifieke taak, bijvoorbeeld gezichten herkennen. Nog verder gaat artificial general intelligence. “Machines met dat type intelligentie kunnen net zoals mensen uiteenlopende intelligente taken vervullen. Het is voor de gevaren achter dat type artificial intelligence dat we vaak worden gewaarschuwd. Maar zover zijn we dus nog niet en zit het grote potentieel vooral in narrow AI.”

Deep learning is dataslokop
De essentie van de neurale netwerken achter deep learning is dat ze zich voeden met data. Dat kunnen bijvoorbeeld pixels met een bepaalde kleur van een foto op je scherm zijn. Vervolgens wordt de informatie op basis van bepaalde criteria ofwel doorgestuurd naar een volgende laag of niet. Dat proces herhaalt zich vervolgens opnieuw en opnieuw. Naarmate de informatie dieper gaat, krijgt het neurale netwerk meer inzichten. Zo kan het neurale netwerk op een bepaald moment stellen dat op een foto pakweg een BMW of een Audi staat. Hoe meer een neuraal netwerk wordt getraind – vergelijk het maar met een biologisch brein – hoe beter het wordt in wat het doet. “In feite is het principe achter zo’n neuraal netwerk vrij eenvoudig”, meent Joren Gijsbrechts. “Neurale netwerken bestaan intussen ook al tientallen jaren en zijn dus op zich evenmin nieuw.”
We kunnen ons dan ook afvragen waarom deep learning nu pas echt een hype wordt. Dat komt omdat we vandaag over heel veel data beschikken. Het is geen toeval dat bedrijven als Google en Amazon pakweg hun eigen homepod hebben. Zij zitten op een massa data én hebben de algoritmes onder de knie. Net omdat ze steeds meer data uit hun omgeving krijgen, worden ze bovendien steeds beter in het ontwikkelen van applicaties. We merken op het vlak van deep learning dan ook een kloof tussen die bedrijven die op een berg data zitten en meer traditionele en kleinere bedrijven.
Een andere reden waarom deep learning steeds populairder wordt, is de open access beschikbaarheid van de laatste algoritmes en de opkomst van cloud computing.
J. Gijsbrechts: “Heel veel trainingsalgoritmes kun je zo van het internet plukken. Daarvoor zorgen mensen zoals Elon Musk, de man achter SpaceX en Tesla. Als je een neuraal netwerk wil trainen, is het ook niet raadzaam om dat op je eigen pc te doen. Pc’s maken gebruik van CPU’s (central processing units) die heel goed zijn in het nemen van seriële beslissingen. Alleen wil je bij deep learning sneller gaan door parallel te leren, om zo tot complexere inzichten te kunnen komen dan bij klassieke algoritmes mogelijk is. Dat kan door GPU’s (graphic processing units) in te zetten. Die worden ook heel vaak gebruikt in de gaming industrie, waar het belangrijk is om niet alleen het spel zelf, maar ook de achtergrond op de juiste manier en zonder vertragingen te laten bewegen. Zulke parallelle processoren worden trouwens ook gebruikt om bitcoins te minen. Die GPU’s zijn de laatste jaren sterk geëvolueerd, wat maakt dat we intussen zeer stevige hardware hebben om deep learning modellen goed te trainen.”

Het drieluik binnen deep learning
Belangrijk om te weten is dat er in wezen drie types deep learning bestaan. Op basis van de informatie die ze gebruiken en de output die ze geven, maken we een onderscheid tussen ‘supervised learning’, ‘unsupervised learning’ en ‘deep reinforcement learning’. Het onderscheid tussen de drie bepaalt immers het potentieel voor hun gebruik binnen supply chain toepassingen.
Supervised learning
Bij supervised learning worden voorspellingen gemaakt op basis van gelabelde data. “Zo gebruikt Google de irritante captcha’s om bijvoorbeeld een perfect zicht te krijgen op hoe verkeerslichten eruitzien. Elke keer dat je zo’n captcha voorgeschoteld krijgt om te bewijzen dat je geen robot bent, voed je de data van Google”, legt prof. Robert Boute uit. “Op die manier krijgt elk van die beelden een label ‘verkeerslicht’ of ‘geen verkeerslicht’. Hoe meer gelabelde beelden er ter beschikking zijn, hoe beter het neurale netwerk wordt getraind en hoe groter de kans is dat het systeem kan inschatten of een beeld een verkeerslicht toont of niet. Zulke zaken kunnen gebruikt worden om zelfsturende wagens verkeerslichten te laten herkennen. Ook Face ID is een mooi voorbeeld van supervised learning.”
Supervised learning is zeer geschikt om bijvoorbeeld demand forecastingmodellen te optimaliseren. Immers, door – liefst zoveel mogelijk – historische gegevens te labelen, kunnen we voorspellingsalgoritmes continu verbeteren en de voorspellingsfout zo klein mogelijk maken.
Ook op het vlak van preventief onderhoud biedt supervised learning perspectieven. Productiemachines capteren namelijk heel veel data op basis van sensoren en dergelijke. Elke keer dat er een storing optreedt, kan die gelabeld worden. Daarbij hoef je de precieze oorzaak zelfs niet te kennen. Op basis van al die labels zullen storingen steeds beter voorspeld kunnen worden, wat een basis kan zijn voor preventief onderhoud en het verbeteren van machines.
Verder kan supervised learning helpen om doorlooptijden beter in te schatten. “Met name productiebedrijven kampen met een grote variatie in doorlooptijden. Door op alle historische data die aan die doorlooptijden gelinkt zijn, een deep learning algoritme los te laten, kunnen we doorlooptijden beter gaan voorspellen. Hetzelfde geldt trouwens voor transporttijden”, illustreert prof. Robert Boute.
Unsupervised learning
In tegenstelling tot supervised learning, maakt unsupervised learning geen gebruik van gelabelde data. Hierbij tracht het algoritme een classificatie te maken van de data. “Stop je bijvoorbeeld de bekende Disney-dieren, zoals Mickey Mouse, Goofy en Donald Duck, in één pot en vraag je om die dieren in twee groepen te catalogeren, dan is de kans groot dat het algoritme Donald Duck en zijn soortgenoten in een aparte groep onderbrengt, gezien hun bek en typische poten”, illustreert prof. Robert Boute.
Binnen supply chain management zijn er volgens Robert Boute vandaag minder use cases voor unsupervised learning: “Wel kan die techniek van pas komen om je klantenbestand op basis van een aantal kenmerken te segmenteren. Als je je supply chain anders aanstuurt per klantensegment, kunnen zulke algoritmes helpen om zo goed mogelijke categorieën te definiëren.”
Deep reinforcement learning
Van een heel andere orde is de laatste categorie. “Deep reinforcement learning kent de laatste paar jaar een enorme doorbraak”, weet Joren Gijsbrechts. “Een van de mooiste voorbeelden van hoe die techniek werkt, is het verhaal achter AlphaGo. Het is algemeen gekend dat computers uitstekende schakers zijn, maar het spel Go is totaal andere koek omdat er immens veel configuraties op het bord kunnen worden gemaakt. Het gaat hier om een getal met maar liefst 170 nullen, wat meer is dan het aantal atomen in ons universum. Het is dus onmogelijk dat spel met gewoon computergeheugen fatsoenlijk te spelen. Deep reinforcement learning daarentegen heeft de intuïtie om te weten op welke positie van het spel je welke actie moet ondernemen. In die wetenschap werd AlphaGo ontwikkeld als reinforcement algoritme dat op basis van data van bestaande spelsituaties is getraind om te winnen. Daarbij werd het neurale netwerk gebruikt om het algoritme via trial-and-error te leren welke acties goed zijn en zo de winstkansen te maximaliseren. Door continu feedback te krijgen over zijn prestaties, werd AlphaGo steeds beter en het algoritme slaagde er zelfs in om de regerende wereldkampioen te verslaan. Lang heeft de roem van AlphaGo evenwel niet geduurd, want enkele weken later betrad AlphaGo Zero de arena. Dat algoritme is gestart van scratch en heeft twee maanden lang enkel tegen zichzelf getraind. Resultaat: AlphaGo Zero heeft AlphaGo verslaan met 100 tegen 0. Klein detail: AlphaGo Zero heeft 25 miljoen dollar aan hardware gekost, dus goedkoop is het niet om zo diep te gaan.”
Een concrete vraag van een belangrijke speler in de FMCG-sector heeft Robert Boute en Joren Gijsbrechts ertoe aangezet het potentieel van deep reinforcement learning nader te gaan onderzoeken.
J. Gijsbrechts: “Het bedrijf in kwestie wilde meer bepaald zijn ecologische voetafdruk verkleinen door meer vrachten van de weg te halen. Het wilde daarom in verschillende omstandigheden kunnen kiezen tussen enerzijds de truck – sneller maar duur – of de trein – trager maar goedkoop – als modal split. Een extra uitdaging was dat hier ook met containertransporten werd gewerkt. Met wiskundige modellen zijn zulke keuzes erg moeilijk te maken, zeker van zodra je er reële data op loslaat.”
Daarom hebben de onderzoekers dat vraagstuk proberen te modelleren als een deep reinforcement learning probleem. Er werd gebruik gemaakt van een volledig geconnecteerd neuraal netwerk en het geavanceerde A3C-algoritme (Asynchronous Advangtage Actor-Critic), wat een van de populaire recent ontwikkelde deep reinforcement algoritmes is. De rekenkracht werd geleverd door het Google Cloud Platform.
Prof. Robert Boute: “Bij dit model bevindt het algoritme zich binnen de tijdsdimensie altijd in een bepaalde toestand, met telkens een welbepaalde voorraad ter plaatse en een bepaalde voorraad in transit. Vanuit die toestand moet het algoritme acties ondernemen. Net zoals de overwinning voor Alpha Go de beloning was, moesten we ook dit algoritme belonen. In dit geval bestond die beloning in een optimale balans tussen minimale kosten en een maximaal serviceniveau. Tijdens de training van het algoritme hebben we het systeem geleerd om steeds beter te worden en om niet enkel beslissingen te nemen die op korte termijn, maar ook op lange termijn de beste zijn.”
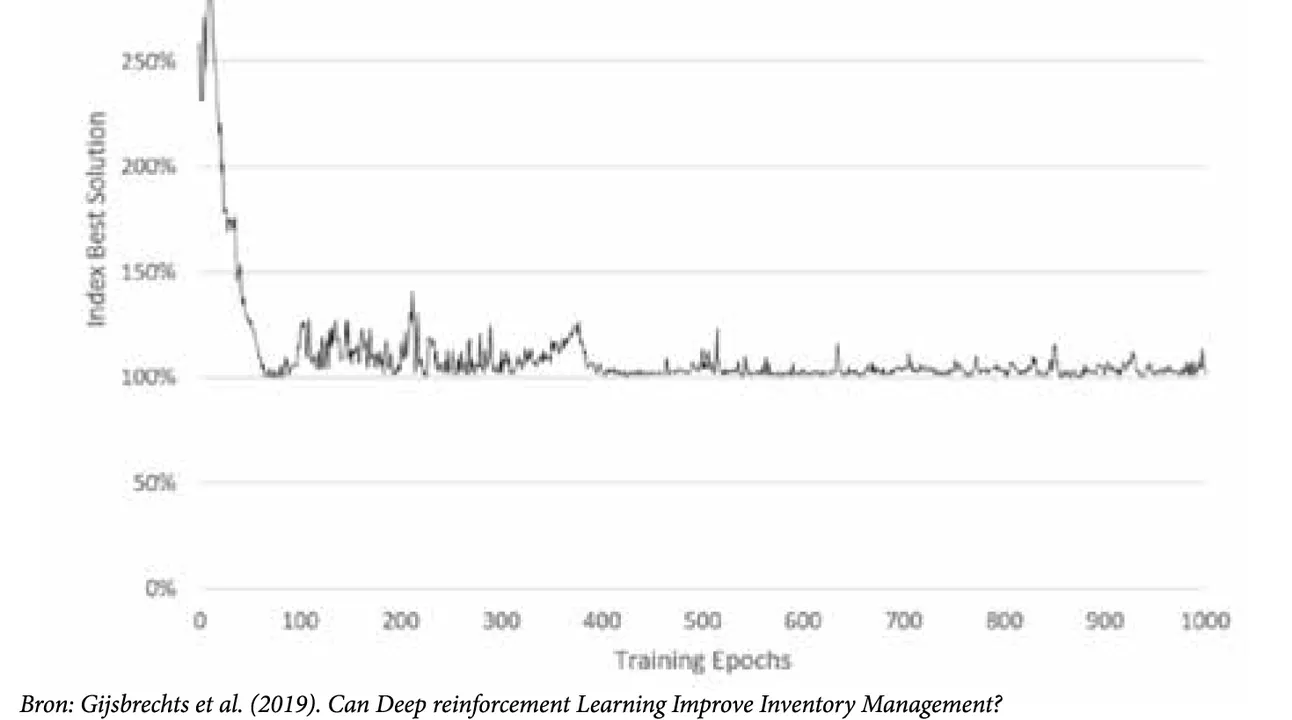
De resultaten van het onderzoek – dat met een beperkt budget werd gerealiseerd – waren opvallend positief. Het algoritme is erin geslaagd voor het reële probleem, met echte data en realistische kostenfuncties, een degelijke bevoorradingsstrategie uit te werken. Concreet zorgde het algoritme ervoor dat de kostenperformantie tijdens de training – gespekt met heel veel simulaties – zeer snel naar beneden ging (zie figuur 3).
J. Gijsbrechts: “Afhankelijk van hoe fel je een bepaalde beloning laat doorwegen, kan de uitkomst variëren. Zo kun je als doelstelling ook de CO2-uitstoot meenemen. Het is mooi om te zien dat de algoritmes zelf leren om goede bevoorradingsregels te vinden. In elk geval zien we echt wel interessante mogelijkheden in supply chain management voor deep reinforcement learning, zeker als het om zeer complexe logistieke problemen gaat.”
“Deep reinforcement learning kan trouwens ook andere types machine learning aanvullen”, stelt prof. Robert Boute. “Zelfs met een perfecte forecast op basis van supervised learning moet je zelf nog bepalen wanneer je gaat bevoorraden. En zelfs wanneer je perfect weet wanneer machines zullen falen, moet je het onderhoud nog zelf optimaal gaan plannen. Tot vandaag worden dergelijke zaken doorgaans nog door mensen opgelost, maar het is niet ondenkbaar dat we ook op dat vlak steeds meer deep reinforcement learning toepassingen zullen zien. De resultaten die we tijdens ons onderzoek hebben geboekt, zijn in elk geval bemoedigend.”
In drie stappen naar deep learning
Omdat alle begin moeilijk is, schuift prof. Robert Boute drie stappen naar voren om van wal te steken met deep learning: “De juiste algoritmes en hardware om aan deep learning te doen zijn er. Het allerbelangrijkste is om data te hebben. Zorg er dus voor dat je datastructuren op orde zijn, dat je weet hoe je de data moet interpreteren, en dergelijke. Heb je te weinig of geen goede data, dan heeft het geen zin om met deep learning algoritmes aan de slag te gaan. In dat geval is het zinvoller om met de traditionele algoritmes het maximum uit je data te halen.”
In een tweede stap raadt prof. Boute aan om de organisatie voor te bereiden op een nieuwe cultuur. “Daarmee wil ik niet zeggen dat beslissingen enkel nog maar door machines zullen worden genomen”, verduidelijkt hij. “Maar je moet er wel voor zorgen dat medewerkers er voor openstaan dat een ‘black box’ pakweg de forecasts naar voren schuift en dat medewerkers daar gerust op kunnen vertrouwen. Voor veel medewerkers is het niet evident om dat te accepteren. In die zin kan dat een struikelblok vormen voor machine learning.”
Tot slot adviseert de professor om met pilootprojecten te starten. “Er zijn intussen massa’s online cursussen rond machine learning beschikbaar en duizenden YouTube-filmpjes die kunnen inspireren. En heb je zelf niet de kennis in huis, dan zijn er experten genoeg die de kennis kunnen leveren”, besluit hij. “Machine learning, en meer bepaald deep learning, is naar mijn mening in elk geval een blijver. De algoritmes kunnen helpen om complexe uitdagingen op het vlak van supply chain management te tackelen, op voorwaarde dat aan de genoemde randvoorwaarden is voldaan. In een wereld waar het steeds belangrijker wordt om snel te zijn is het ook aan te raden om projecten niet al te lang uit te stellen, willen we niet ingehaald worden door bedrijven die sneller zijn.”



