Zorg dat je met geldige data werkt
Alexander Silantyev over het belang van Measurement System Analysis

Bedrijven moeten zich continu heruitvinden en continu optimaliseren. Projecten worden opgestart op basis van gegevens die aantonen dat we er veel baat bij zullen hebben. Maar van waar komen die gegevens? Zijn ze relevant en correct? Bovendien worstelen veel bedrijven met het feit dat elke afdeling zijn eigen data heeft en zo ook zijn eigen waarheid. We moeten dus kritisch met gegevens omspringen. Alexander Silantyev, manager bij PwC Advisory en gecertificeerd als Lean Six Sigma Master Black Belt, vertelt ons in deze bijdrage hoe we met data moeten omgaan, hoe we de geldigheid van data kunnen controleren.
Toen ik een Green Belt- en Black Belt-opleiding aan het volgen was, zag ik de waarde van ‘Measurement System Analysis’ (MSA) nog niet helemaal in. In mijn ogen was het een concept dat werkte, maar dan iets dat je gebruikt in één op tien projecten – alleen als het duidelijk is dat je onderzoek kunt doen met de mogelijkheid om de herhaalbaarheid en reproduceerbaarheid (‘repeatability & reproducibility’, kort ‘R&R’) te bepalen.
Na mijn opleiding tot Master Black Belt ging ik aan de slag bij Anheuser-Busch InBev, waar ik Green Belt-projectcoachingsessies begon bij te wonen. Vervolgens begon ik zelf projecten te coachen en Green Belts en Black Belts op te leiden. Telkens als we het over de meetfase hadden, hoorde ik wel iemand, en dan vooral projectleiders uit andere domeinen dan productie, zeggen: “Ja, maar hoe is MSA op mij van toepassing? Ik verbeter het marktaandeel, daar kan ik niks doen met ‘gage R&R’.”
Nu ik inmiddels met verscheidene instructeurs heb samengewerkt, vind ik nog altijd dat een goed algemeen overzicht van de problematiek ontbreekt. Het is niet moeilijk om toelichting te vinden over de ijkingsgerelateerde herhaalbaarheid en reproduceerbaarheid (gage R&R) of het analyseren van overeenkomsten tussen eigenschappen (attribute agreement analysis), maar er is geen goede leidraad beschikbaar over hoe je MSA het best toepast in genuanceerde praktijkgevallen.
Kies de juiste KPI
Bij elk optimaliseringsproject komen er per definitie data aan te pas. Of zoals Peter Drucker, de grondlegger van modern management, zei: “You can’t improve what you don’t measure.” Met andere woorden, zonder data kunnen we misschien wel zaken verbeteren, maar zullen we nooit kunnen bewijzen dat we daar effectief in geslaagd zijn. Dat is de reden waarom er in alle projectmanagementopleidingen op wordt gehamerd dat doelstellingen SMART moeten zijn: specifiek, meetbaar, acceptabel (in de zin van haalbaar), relevant en tijdsgebonden.
Wat ook van belang is, is het juiste niveau van de KPI (key performance indicator). In de productiesector meet ieder bedrijf zijn eigen performantie op fabrieksniveau en op het niveau van elke machine. Maar om de processen te verbeteren volstaat dat niet.
Voorbeeld uit de productie
Nemen we een voorbeeld uit de productie. Een fabrikant wil de ‘overall equipment efficiency’ (OEE) van een verpakkingslijn verbeteren. Voor een grondige analyse passen we het Pareto-principe toe. Als er geen verfijnd meetsysteem voorhanden is, moet dat worden ingesteld. Maar laat ons veronderstellen dat we wel over zo’n meetsysteem beschikken. We delen de OEE dan op in categorieën en stellen vast dat de geplande downtime (stilstand) dertig procent van het totale capaciteitsverlies vertegenwoordigt; er gaat te veel tijd naar omstellingen. In de volgende stap moeten we dan nagaan hoeveel omstellingen er zijn en hoeveel tijd elke omstelling in beslag neemt. Vervolgens moeten we de SMED-benadering (single minute exchange of dies) toepassen om de omsteltijd te verkorten. De geschikte primaire maatstaf voor dit project zou de gemiddelde omsteltijd kunnen zijn. Deze moet dan op een betrouwbare wijze worden gemeten. Maar hoe kunnen we zeker zijn dat het bekomen getal betrouwbaar is?
Voorbeeld uit een andere sector dan productie
Laten we nu een voorbeeld nemen uit een niet-productiecontext. De logistieke afdeling van een FMCG-onderneming (fast-moving consumer goods) wil het aantal gevallen van niet-conformiteit inzake ‘on time, in full’ (OTIF) leveringen die het gevolg zijn van transportgerelateerde problemen, verminderen.
Een ‘service level’-gerelateerde KPI is niet verfijnd genoeg om hierin klaarheid te scheppen. We moeten kijken naar categorieën binnen het service level. Het is echter verkeerd om binnen het totaalplaatje slechts het aandeel transportgerelateerde problemen te willen verminderen. Het is namelijk mogelijk dat die KPI gewoonweg verbetert omdat een andere OTIF-categorie verslechtert. Een gepaste KPI zou hier het percentage zijn dat het aantal transportgerelateerde problemen inneemt in het totale aantal transporten.
Nu we de geschikte KPI hebben gekozen, moeten we de uitgangswaarde vaststellen, de performantie verbeteren en het verschil aantonen, ja toch? Nee, zover zijn we nog niet. We moeten er namelijk eerst voor zorgen dat we de cijfers kunnen vertrouwen.
Kies de geschikte methode om data te valideren
Als we een project hebben dat met het verbeteren van KPI’s verband houdt, hoe valideren we dan de nauwkeurigheid van de data? Algemeen gesteld moeten we bekijken of we het een meting opnieuw kunnen plannen en herhalen teneinde de meetmethode te controleren, of kunnen we dat niet. Maar zelfs al beschikken we alleen over bestaande historische data, dan nog kan er veel worden gedaan om te beoordelen in hoeverre het meetsysteem als betrouwbaar mag worden beschouwd.
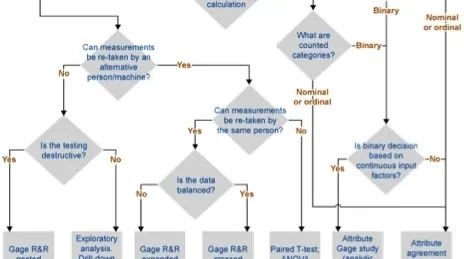
Figuur 1 geeft het traject weer om het juiste algoritme te vinden om tot de geschikte validatiemethode te komen.
Ter illustratie van dit beslissingsschema volgen hier enkele voorbeelden:
1. Een drankenproducent maakt flessen met een draaidop. De kracht die nodig is om een dop los te schroeven, moet worden gemeten. Het gaat over continue data die rechtstreeks met een toestel worden gemeten. Maar de metingen voor dezelfde flessen kunnen niet worden overgedaan omdat het een destructieve test is. Dus moet in dit geval de ‘nested gage R&R’ methode worden toegepast.
2. Een brouwerij produceerde de voorbije jaren een beperkte hoeveelheid van een speciaal merk. Wegens klachten van consumenten – we vermoeden dat het product te bitter werd bevonden – wordt het bier niet meer geproduceerd. We hebben geen toegang tot de kwaliteitscontrole, maar we beschikken wel over historische data. De bitterheid zou continu kunnen worden gemeten, maar we kunnen de tests niet overdoen. We moeten het procedé van de ‘exploratory data analysis (‘EDA’) toepassen om een veronderstelling te maken of de cijfers al dan niet betrouwbaar zijn.
3. Een drukkerij gebruikt in de productieproces vloeibare inkt. Om goede kwaliteit te kunnen leveren, moet de inkt de gepaste viscositeit hebben. Die wordt bij de drukmachines gemeten door de operators die de machines bedienen. Viscositeit wordt onrechtstreeks gemeten als het aantal seconden dat de inkt nodig heeft om uit een standaard meettrechter te lopen. Het gaat dus om continue data die rechtstreeks worden gemeten. We kunnen zowel de herhaalbaarheid als de reproduceerbaarheid meten. Beschikken we over evenwichtige data (d.w.z. een gelijk aantal metingen per monster tussen en bij operators en/of meettoestellen), dan kiezen we voor een klassieke ‘gage R&R crossed’ methode.
Zijn de data niet evenwichtig of willen we bijkomende factoren in aanmerking nemen (bv. wisselwerking tussen verschillende operators en verschillende meettoestellen), dan kiezen we voor een uitgebreide Gage R&R.
4. Een staalbedrijf probeert zijn totale elektriciteitsverbruik te verminderen. De meting gebeurt door de meter in de fabriek. Die meter is gekalibreerd, maar in hoeverre kunnen we daarop vertrouwen? Het betreft continue data die rechtstreeks worden gemeten, maar er is geen manier om de test over te doen. De enige vorm van verificatie bestaat erin een alternatief meetsysteem te vinden en vervolgens de cijfers door middel van een gekoppelde T-test te vergelijken. Dit alternatief kan de ter beschikking gestelde elektriciteitsmeter zijn of de som van de afzonderlijke meters die in de fabriek opgesteld zijn (in beide gevallen moeten we ook rekening houden met stroomnetverlies). Met deze methode zullen we nooit exact weten in hoeverre we het meetsysteem kunnen vertrouwen. Wat we er wel mee te weten komen, is het ‘betrouwbaarheidsinterval van verschil’ tussen twee of meer waarden die afkomstig zijn van verschillende meetsystemen, zodat we kunnen beslissen of we dat verschil al dan niet aanvaardbaar vinden. Opgelet: de ‘analysis of variance’ (ANOVA) en de -test gaan uit van normale data. Voor niet-normale data moeten we de respectieve niet-parametrische tests gebruiken.
5. Een farmaceutische verpakkingslijn heeft een besturingseenheid die elke verpakking verwerpt waarvan het gewicht onder de toegestane afwijking ligt. Dat kan bijvoorbeeld voorkomen wanneer een bijsluiter ontbreekt. ‘Discrete output’ (aanvaarden/verwerpen) is hier een functie van ‘continue input’ (gewicht in gram). Om de nauwkeurigheid van deze besturingseenheid te bepalen, is er dus een ‘attribute gage’-gerelateerde onderzoeksmethode nodig.
6. Tijdens een sollicitatiegesprek evalueren de beoordelaars op een schaal van 1 tot 5 in hoeverre een sollicitant past binnen de bedrijfscultuur. Op basis van deze en andere factoren kan iemand anders beslissen of een kandidaat de job aangeboden krijgt. In het eerste geval betreft het een niet-continue (‘discrete’) ordinale meting (alleen gehele getallen zijn mogelijk). In het tweede geval gaat het om discrete binaire gegevens (ja/neen). In beide gevallen kunnen we ‘attribute agreement analysis’ toepassen.
Voorbeelden van ‘exploratory data analysis’
Enkele eenvoudige instrumenten voor grafische analyse kunnen ons meer vertellen dan duizend woorden. Men zegt wel eens dat er wat data betreft slechts drie regels bestaan: Regel één: zet de data uit in een grafiek. Regel twee: zet de data uit in een grafiek. En regel drie: zet de data uit in een grafiek. Voor onze toepassing betekent dit dat we ons moeten focussen op het datadistributiepatroon, de evolutie van het proces met het verloop van de tijd en de eventuele aanwezigheid van abnormaliteiten. Deze stappen kunnen helpen bepalen of er met de data iets mis is. Hierna volgen twee voorbeelden.
Voorbeeld 1: bitterheid van bier
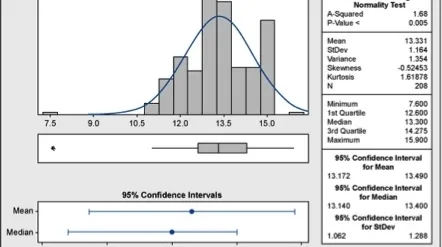
Uit de grafische samenvatting van Minitab in figuur 2 blijkt dat deze data niet normaal zijn. Ze vertonen een tri-modaliteit (een opvallende piek op drie plaatsen) die veroorzaakt kan zijn door ofwel verschuivingen in het proces ofwel andere factoren.
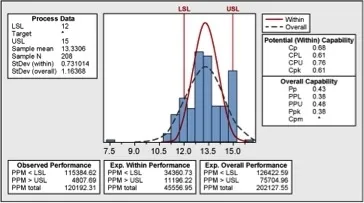
Geen enkel natuurlijk proces kan op deze manier worden verklaard. Bijgevolg kunnen we geen betrouwbare besluiten trekken voordat we de aard van deze abnormaliteit begrijpen. Zou het kunnen dat de piek op 12, 15 respectievelijk 18 eenheden te maken heeft met de processpecificaties? Ja. Wat de toleranties betreft, zijn de ondergrens en de bovengrens vastgelegd op 12 respectievelijk 18, wat de middenwaarde (en het streefcijfer) op 15 brengt. Dat kunnen we zien in de capaciteitsanalyse (‘capability analysis’) in figuur 3.
Tot op zekere hoogte werden data gemanipuleerd, waarbij de gemeten waarden (vooral degene die de bovengrens overschrijden) werden afgerond op het aanvaardbare cijfer. Gelukkig laat een capaciteitsanalyse zien hoe het echte proces eruitziet.
De praktische conclusie hier is dat de historische data niet betrouwbaar waren. Het hele meet- en registratieproces was aan verbetering toe.
Voorbeeld 2: gebruik van lijm
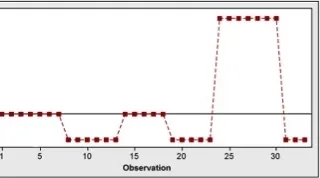
Een van de verrichtingen die bij het maken van bierverpakkingen komt kijken, is het aanbrengen van etiketten op de flessen. Daarvoor wordt gebruik gemaakt van gesmolten lijm. Het verbruik van deze lijm wordt opgevolgd en gerapporteerd. Voor de optimalisering van het lijmverbruik moeten we eerst naar de historische data kijken (figuur 4).
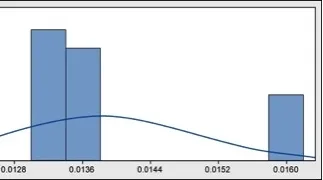
Zelfs zonder dat een p-waarde wordt bekomen, is het duidelijk dat de data niet normaal zijn. Hoe zou dat komen? Een blik op een tijdreeks (figuur 5) kan dat misschien helpen verklaren.
Wat het histogram weergaf, was een wekelijkse uitmiddeling – niet het dagelijkse verbruik. Effectieve metingen werden duidelijk eenmaal per week uitgevoerd, en elk cijfer werd over meerdere dagen uitgevlakt. Rapportering over dagelijks verbruik was een vereiste, maar niemand leek problemen te hebben met gelijke cijfers van dag tot dag.
Als gevolg daarvan begonnen dagelijkse effectieve metingen plaats te vinden, wat veel gedetailleerdere informatie opleverde om in de toekomst processen te optimaliseren.
Stel je kritsich op
Ongeacht welk proces we willen optimaliseren, data hebben we altijd nodig. Telkens als we gebruik maken van data, moeten we ons kritisch opstellen ten opzichte van de nauwkeurigheid van die data. Als er een statistische analyse mogelijk is om de meetfout te schatten, dan moet die worden uitgevoerd. Kan een dergelijke analyse niet worden uitgevoerd, dan moeten we er op een indirecte manier proberen achter te komen in hoeverre we op het betreffende meetsysteem kunnen vertrouwen.
Alexander Silantyev
Over de auteur
Alexander Silantyev is manager bij PwC Advisory en is gecertificeerd als Lean Six Sigma Master Black Belt. De afgelopen jaren heeft hij meer dan honderd bedrijfsverbeteringsprojecten gecoacht en verschillende projecten zelf uitgevoerd. Hij is gespecialiseerd in Lean initiatieven en onderhoudsprojecten, maar kan ook verschillende Continuous Improvement activiteiten leiden en ondersteunen.



