Zoek de fout in je supply chain processen
Process mining als procesverbeteraar in digitale tijden

Van bedrijven wordt meer dan ooit verwacht dat ze in hun supply chain geen steken laten vallen. In die context wordt het steeds belangrijker onze processen te optimaliseren. Dat impliceert dat we in staat moeten zijn fouten of verbeteringspotentieel tijdig te spotten. Een tool om verborgen pijnpunten op een efficiënte manier bloot te leggen, is ‘process mining’. Jochen De Weerdt, associate professor aan het Departement of Decision Sciences & Information Management van de KU Leuven, belicht de waarde van de tool.
Door de toenemende digitalisering verzamelen we steeds meer data in onze supply chains. “Dat maakt het steeds interessanter om die data te ‘minen’ en zo bedrijfsprocessen te analyseren”, legde Jochen De Weerdt uit tijdens een seminar dat valueXstream met Pics Belgium organiseerde. “Process mining stelt ons in staat modellen te bouwen die het échte netwerk van stromen in de organisatie blootleggen. Die uitkomst laat toe toekomstige stromen beter te voorspellen en geeft het management nieuwe inzichten. Verder komen anomalieën sneller aan het licht, waardoor tijdig actie kan worden ondernomen.”

Processen onder de loep
De essentie van process mining is dat er handig gebruik wordt gemaakt van de data in de aanwezige processen. Processen vormen nu eenmaal de hoeksteen van bedrijven. Als we analyses willen uitvoeren, is een procesinsteek vaak een heel nuttig startpunt. Hoe wordt het werk georganiseerd, wie is betrokken en hoe kunnen we het een en ander efficiënter stroomlijnen? Het antwoord op die vragen is bovendien voor de meest diverse sectoren interessant.
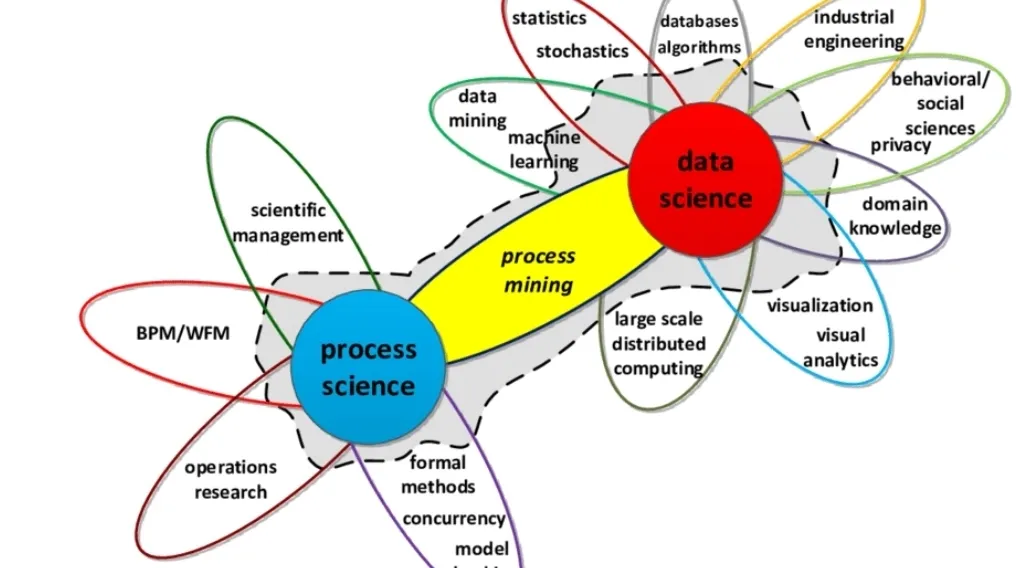
Process mining kunnen we zien als een waardevolle aanvulling op andere analysetechnieken in de context van business process management. De techniek situeren we het best in de overlapping tussen enerzijds het ruime begrip van de ‘data science’ en anderzijds de ‘process science’, met de verschillende technieken om processen te bestuderen, te kwantificeren en te visualiseren (zie figuur 1). Om met process mining aan de slag te gaan, zij we dus idealiter vertrouwd met zowel business process management als data-analyse.
Gelukkig is process mining intussen ook toegankelijk voor minder ervaren rotten in die domeinen. In de laatste vijftien jaar is process mining relatief matuur geworden, wat heeft geleid tot een aantal laagdrempelige commerciële tools waarmee we snel aan de slag kunnen. Toch blijft het belangrijk om vooraf goed te weten wat we van process mining mogen verwachten en wat niet. Bovendien zijn er aan het gebruik van de tool een aantal voorwaarden verbonden.
Karakteristieken van process mining
Het eerste wat we moeten doen als we met process mining aan de slag willen gaan, is één bepaald proces afbakenen.
Jochen De Weerdt: “Ook gaan we er bij process mining van uit dat je een of meerdere informatiesystemen gebruikt om de uitvoering van het proces te ondersteunen. Dat kan je ERP of een andere applicatie zijn. Die houdt bij welke stappen in het proces plaatsvinden. In process mining terminologie noemen we dat ‘event logs’. Ze geven bijvoorbeeld aan op welk moment een evenement plaatsvond en wanneer het werd afgerond.”
In een event log refereert elk event aan een bepaalde activiteit, die zich voordoet in de context van een bepaalde case. Zo’n event staat gelijk aan een rij binnen je dataset, die aangeeft dat een bepaalde activiteit in een bepaalde case werd uitgevoerd. Met ander woorden, een event log is een verzameling van cases (met elk hun case ID) en elke case is een opeenvolging van events. Als we alle event logs uit onze databronnen tot één dataset combineren, kunnen we daar vervolgens process mining op toepassen.
J. De Weerdt: “Een aantal zaken zijn zeer karakteristiek voor process mining. Om te beginnen verwijzen meerdere events dus naar hetzelfde case ID. Meestal zijn dat er tussen de tien en de 150 per case. Dat is anders dan bij traditionele analytics, waarbij elke rij in principe onafhankelijk is. Dat impliceert meteen ook dat je een set activiteiten moet kunnen definiëren waaraan elk event refereert. Ook dat is typerend voor process mining. Een derde kenmerk is dat je aan elk event een ‘timestamp’ moet kunnen geven. Samengevat: als je process mining wilt toepassen, moet je nagaan of je events kunt koppelen aan case ID’s, of je labels aan activiteiten kunt toekennen én of de nodige timestamps aanwezig zijn. Pas als je die drie zaken kunt afvinken, kun je met process mining van wal steken.”
Process mining is een kunst
Ook belangrijk om te weten is dat er bij process mining drie soorten technieken gangbaar zijn. Ten eerste zijn er ‘process discovery’ technieken. Die laten toe zuiver op basis van de data een procesmodel te bouwen. Ten tweede zijn er de ‘conformance checking’ technieken. Daarbij vergelijken we onze daadwerkelijke processen met een normatief model, dat weergeeft hoe we verwachten dat het proces er uitziet. Tot slot zijn er de extensietechnieken, die modellen verrijken aan de hand van een event log. Een goed voorbeeld is de visualisatie van bottlenecks in het procesmodel.In wat volgt, zullen we meer bepaald op de process discovery en de conformance checking technieken inzoomen.
Process discovery technieken
Bij process mining als discovery techniek worden een aantal gekende manuele technieken vervangen. We denken hier met name aan de traditionele interviews en workshops die worden gebruikt om processen te reconstrueren en zo een beeld van de realiteit te krijgen. Aan die gekende manier van werken zitten evenwel een paar haken en ogen vast. Zo krijg we via interviews nooit een honderd procent juiste weergave van de realiteit. Process mining is objectiever en bovendien veel minder tijdrovend.
Met het oog op process discovery heeft de academische wereld intussen een reeks sterke algoritmes uitgebouwd die we op event logs kunnen loslaten.
J. De Weerdt: “Op het eerste gezicht lijkt process mining vrij simpel, maar niets is minder waar. Met process discovery is het probleem dat je meerdere dimensies tegelijk moet meenemen. Als je pakweg 10.000 cases evalueert, dan moet je in staat zijn elke event log opnieuw af te spelen om te kunnen bekijken welke ‘toegelaten’ zijn. We spreken hier over de ‘fitness’ van je model.
Er zijn evenwel heel wat ‘fitting’ modellen die toch niet goed genoeg zijn. Immers, je moet de grenzen binnen je model goed bepalen, om zo de juiste precisie te krijgen. Je moet voldoende breed gaan om representatief te zijn, maar je mag ook niet per se alle stromen willen meenemen. Tegelijk moet het model kunnen generaliseren. Zo is het best mogelijk dat je zes maanden aan data capteert en toch niet elke variant van je proces hebt zien passeren. Je model moet dus ook een andere variant kunnen toelaten, als die in lijn ligt met de varianten binnen je startmodel. Die drie dimensies – fitness, precisie en generalisatie – tegelijk optimaliseren is erg complex. Alleen complexe algoritmes kunnen daar echt goed mee overweg.”
Toch worden complexe algoritmes in process mining vrijwel alleen in de academische wereld gebruikt. “De commerciële tools die vandaag beschikbaar zijn, zijn meer gericht op de creatie van bevattelijke ‘flow maps”, vertelt Jochen De Weerdt. “Daarbij volstaan eerder eenvoudige algoritmes. Er lopen weliswaar een aantal initiatieven om die algoritmes op een hoger niveau te tillen, maar daar mag je zeker niet van uitgaan als je zo’n tool aanschaft.”
Wil dat zeggen dat commerciële tools slecht zijn? Helemaal niet. Het voordeel is dat ze heel overzichtelijk zijn doordat ze abstractie maken van de data. Dat geeft een goed beeld van hoe onze processen in elkaar steken. Het nadeel is dat ze meestal niet erg precies zijn en eerder een ruwe schets van de processen geven.
J. De Weerdt: “Het is vooral belangrijk dat je die flow maps met een korreltje zout neemt. Als je bepaalde zaken echt tot in detail wilt gaan uitspitten, verifieer je toch beter de data zelf in het systeem. Zo vermijd je dat je de verkeerde conclusies trekt.”
Conformance checking technieken
Bij de conformance checking technieken gebeurt een discrepantie-analyse tussen het geobserveerde gedrag en het gedrag in het normatieve model. “Daarbij kun je nagaan welk percentage van alle cases in je model passen, negentig procent bijvoorbeeld. Op basis daarvan kun je dan je globale perfomantie (over de tijd heen) bepalen”, licht Jochen De Weerdt toe. “Dat klinkt opnieuw eenvoudig, maar de algoritmes die wij daarvoor gebruiken, zijn vrij complex. Aan de hand daarvan is het mogelijk exact te bepalen of een case al dan niet in het model past.”
Vaak is het nog interessanter om de lokale diagnostiek onder de loep te nemen. Zo kunnen we gaan bepalen waar in onze processen het vaak fout loopt. Met behulp van conformance checking technieken kunnen we bijvoorbeeld ontdekken dat er vaak handtekeningen worden gezet op een moment dat dat eigenlijk nog niet mag. Vervolgens kunnen we nagaan waarom het normatieve proces niet wordt gevolgd. Een groot voordeel van conformance checking technieken is dat we zulke dingen voor alle cases tegelijk kunnen nagaan. Dat manueel doen, is onbegonnen werk. Met conformance checking technieken kunnen we ook verbeteringsmogelijkheden spotten. Misschien wijken medewerkers wel van het normatieve model af omdat hun manier van werken efficiënter is. Dan is het slimmer om het proces aan te pakken in plaats van de deviaties.
Tot voor kort vonden we in de huidige commerciële pakketten geen of slechts zeer beperkte conformance checking technieken terug.
J. De Weerdt: “In de software van Celonis, marktleider op het vlak van process mining, zitten die technieken tegenwoordig wel geïntegreerd. De software laat toe een normatief model in te geven en gaat vervolgens na welke cases conform zijn met dat model. Tot vandaag zijn de pakketten die dat kunnen eerder de uitzondering dan de regel, maar we merken wel dat aanbieders toch steeds meer de ambitie hebben om meer dan enkel process discovery technieken aan te bieden.”
Uitdagingen bij process mining
Dat process mining in het huidige landschap vol gedigitaliseerde processen toegevoegde waarde kan bieden, staat buiten kijf. Toch moeten we met een aantal aandachtspunten rekening houden om process mining te doen slagen.
Om te beginnen moet de kwaliteit van de data voldoende zijn. Halen we data uit meerdere systemen, dan moeten bijvoorbeeld de case ID’s overeenstemmen. Ook moeten we er rekening mee houden dat events in een event log per case worden gegroepeerd. Dat kan voor uitdagingen zorgen, aangezien de events met elkaar gecorreleerd moeten zijn. Verder moet het mogelijk zijn de events via timestaps per case te ordenen. Typische problemen die daarbij kunnen opduiken, is dat enkel de data beschikbaar zijn of dat niet alle klokken gelijk staan. Ook komt het vaak voor dat er vertraging in de logging zit. Verpleegkundingen in een ziekenhuis, bijvoorbeeld, hebben de neiging eerst hun taken in de patiëntenkamers af te werken en pas achteraf alle gegevens in te voeren. Dat zorgt uiteraard voor een vertekend beeld.
J. De Weerdt: “Het is een feit dat bedrijven die nog niet met process mining bezig zijn, hier automatisch minder aandacht aan besteden. Wees dan ook niet teleurgesteld als je heel wat lege en foutieve velden tegenkomt als je voor het eerst een dataset uit je systeem haalt.”
Een ander probleem is de scoping van de data. “Zeker datastructuren in ERP-pakketten zijn uitdagend om mee te werken”, weet Jochen De Weerdt. “Data worden geregeld op andere manieren in het systeem opgeslagen, waardoor je toch wat transformaties nodig hebt om tot een uniforme structuur te komen. Het is ook niet altijd duidelijk welke tabellen interessante data bevatten om mee te nemen en welke niet.”
Ook de granulariteit van de data kan een probleem vormen. Zo kunnen log events eerder technisch zijn en bijgevolg niet handig om analyses vanuit businessperspectief op uit te voeren. In dat geval zal er relatief complexe data engineering nodig zijn om events in functie van de daadwerkelijke business events te extraheren.
Daarnaast schrikken mensen er vaak van dat het procesmodel dat ze uit een dataset halen vele malen complexer is dan wat ze verwachtten.
J. De Weerdt: “In supply chain management, bijvoorbeeld, zijn de processen in het hoofd van velen eenvoudig, met weinig variaties. Dan valt het erg tegen wanneer het eerste model dat je krijgt helemaal niet zo gestructureerd is. Dat zal zeker zo zijn als je met academische algoritmes aan de slag gaat. Het is belangrijk dat je daarop voorbereid bent. Besef ook dat je alleen met de juiste business kennis zal kunnen plaatsen wat de tool je toont. Bij commerciële pakketten zul je dat ‘schrikeffect’ veel minder hebben, aangezien zij sterk vereenvoudigd zijn. Maar als je dieper in die modellen wilt graven, zul je ook hier die business kennis opnieuw hard nodig hebben. Dat neemt niet weg dat je op basis van die ruwe modellen wellicht toch al enkele ‘quick wins’ zult kunnen spotten.”
En last but not least, mogen we van process mining nog niet veel verwachten op het vlak van ‘predictive analytics’. De aangehaalde technieken, process discovery en conformance checking, passen immers eerder in het concept van de ‘descriptive analytics’.
J. De Weerdt: “Uiteraard zou het fijn zijn als de technieken nog meer een beeld zouden geven van wat we in de toekomst kunnen of moeten doen. Predictive analytics wordt in de wereld van vandaag ook steeds belangrijker. We doen momenteel heel veel onderzoek naar hoe we process mining meer in die richting kunnen doen evolueren. Intussen merken we dat process mining de laatste jaren echt wel een hype aan het worden is en dat er steeds meer commerciële aanbieders opduiken die daar op inpikken. Ongetwijfeld zullen ook zij inspanningen leveren om process mining op een steeds hoger niveau te krijgen. Dat kan de verdere evolutie van process mining alleen maar ten goede komen.”
TC


